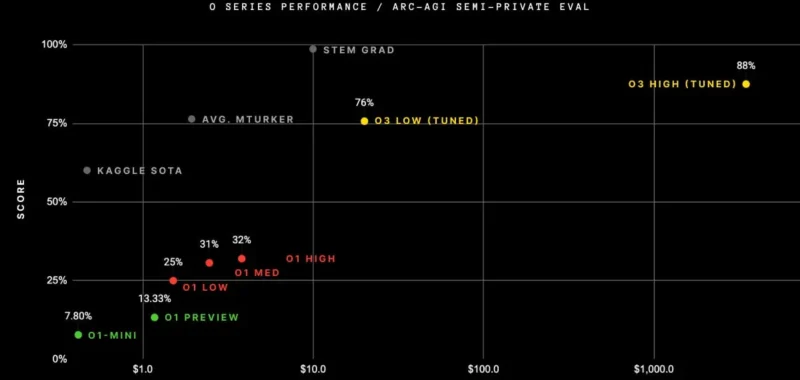
OpenAI’s latest AI model family has achieved what many thought impossible, scoring an unprecedented 87.5% on the challenging, so-called Autonomous Research Collaborative Artificial General Intelligence benchmark—basically near the minimum threshold for what could theoretically be considered “human.”
The ARC-AGI benchmark tests how close a model is to achieving artificial general intelligence, meaning whether it can think, solve problems, and adapt like a human in different situations… even when it hasn’t been trained for them. The benchmark is extremely easy for humans to beat, but is extremely hard for machines to understand and solve.
The San Francisco-based AI research company unveiled o3 and o3-mini last week as part of its “12 days of OpenAI” campaign—and just days after Google announced its own o1 competitor. The release showed that OpenAI’s upcoming model was closer to reaching artificial general intelligence than expected.
OpenAI’s new reasoning-focused model marks a fundamental shift in how AI systems approach complex reasoning. Unlike traditional large language models that rely on pattern matching, o3 introduces a novel “program synthesis” approach that allows it to tackle entirely new problems it hasn’t encountered before.
“This is not merely incremental improvement, but a genuine breakthrough,” the ARC team stated in their evaluation report. In a blog post, ARC Prize co-founder Francois Chollet went even further, suggesting that “o3 is a system capable of adapting to tasks it has never encountered before, arguably approaching human-level performance in the ARC-AGI domain.”
Just for reference, here is what ARC Prize says about its scores: “The average human performance in the study was between 73.3% and 77.2% correct (public training set average: 76.2%; public evaluation set average: 64.2%.)”
OpenAI o3 achieved an 88.5% score using high computing equipment. That score was leaps ahead of any other AI model currently available.
Is o3 AGI? It depends on who you ask
Despite its impressive results, the ARC Prize board—and other experts—said that AGI has not yet been achieved, so the $1 million prize remains unclaimed. But experts across the AI industry were not unanimous in their opinions about whether o3 had breached the AGI benchmark.
Some—including Chollet himself—took issue with the whether the benchmarking test itself was even the best gauge of whether a model was approaching real, human-level problem-solving: “Passing ARC-AGI does not equate to achieving AGI, and as a matter of fact, I don’t think o3 is AGI yet,” Chollet said. “O3 still fails on some very easy tasks, indicating fundamental differences with human intelligence.”
He referenced a newer version of the AGI benchmark, which he said would provide a more accurate measure of how close an AI is to being able to reason like a human. Chollet noted that “early data points suggest that the upcoming ARC-AGI-2 benchmark will still pose a significant challenge to o3, potentially reducing its score to under 30% even at high compute (while a smart human would still be able to score over 95% with no training).”
Other skeptics even claimed that OpenAI effectively gamed the test. “Models like o3 use planning tricks. They outline steps (“scratchpads”) to improve accuracy, but they’re still advanced text predictors. For example, when o3 ‘counts letters,’ it’s generating text about counting, not truly reasoning,” Zeroqode co-founder Levon Terteryan wrote on X.
Why OpenAI’s o3 Isn’t AGI
OpenAI’s new reasoning model, o3, is impressive on benchmarks but still far from AGI.
What is AGI?
AGI (Artificial General Intelligence) refers to a system capable of human-level understanding across tasks. It should:
– Play chess like a human.… pic.twitter.com/yn4cuDTFte— Levon Terteryan (@levon377) December 21, 2024
A similar point of view is shared by other AI scientists, like the award-winning AI researcher Melanie Mitchel, who argued that o3 isn’t truly reasoning but performing a “heuristic search.”
Chollet and others pointed out that OpenAI wasn’t transparent about how its models operate. The models appear to be trained on different Chain of Thought processes “in a fashion perhaps not too dissimilar to AlphaZero-style Monte-Carlo tree search,” said Mitchell. In other words, it doesn’t know how to solve a new problem, and instead applies the most likely Chain of Thought possible on its vast corpus on knowledge until it successfully finds a solution.
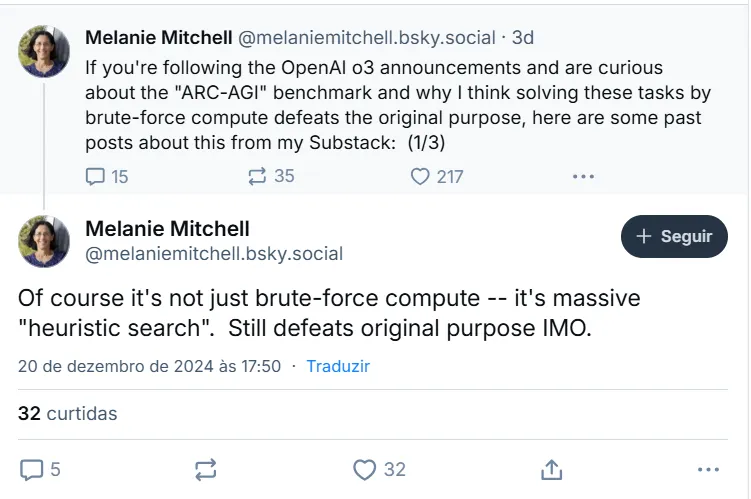
In other words, o3 isn’t truly creative—it simply relies on a vast library to trial-and-error its way to a solution.
“Brute force (does not equals) intelligence. o3 relied on extreme computing power to reach its unofficial score,” Jeff Joyce, host of the Humanity Unchained AI podcast, argued on Linkedin. “True AGI would need to solve problems efficiently. Even with unlimited resources, o3 couldn’t crack over 100 puzzles that humans find easy.”
OpenAI researcher Vahidi Kazemi is in the “This is AGI” camp. “In my opinion we have already achieved AGI,” he said, pointing to the earlier o1 model, which he argued was the first designed to reason instead of just predicting the next token.
He drew a parallel to scientific methodology, contending that since science itself relies on systematic, repeatable steps to validate hypotheses, it’s inconsistent to dismiss AI models as non-AGI simply because they follow a set of predetermined instructions. That said, OpenAI has “not achieved ‘better than any human at any task,’ ” he wrote.
In my opinion we have already achieved AGI and it’s even more clear with O1. We have not achieved “better than any human at any task” but what we have is “better than most humans at most tasks”. Some say LLMs only know how to follow a recipe. Firstly, no one can really explain…
— Vahid Kazemi (@VahidK) December 6, 2024
For his part, OpenAI CEO Sam Altman isn’t taking a position on whether AGI has been reached. He simply said that “o3 is a very very smart model,” and “o3 mini is an incredibly smart model but with really good performance and cost.”
Being smart may not be enough to claim that AGI has been achieved—at least yet. But stay tuned: “We view this as sort of the beginning of the next phase of AI,” he added.
Edited by Andrew Hayward